
微博项目(1):爬取用户微博内容

此爬虫练习为微博项目中获取数据的第一步,项目整体目标为对 Super Junior(或任意明星团体)的微博数据进行分析。
微博项目中的爬虫练习:根据待爬对象微博url,获取该对象指定页数的weibo(包括内容、内容形式、发送时间、发送平台、转赞评等)。
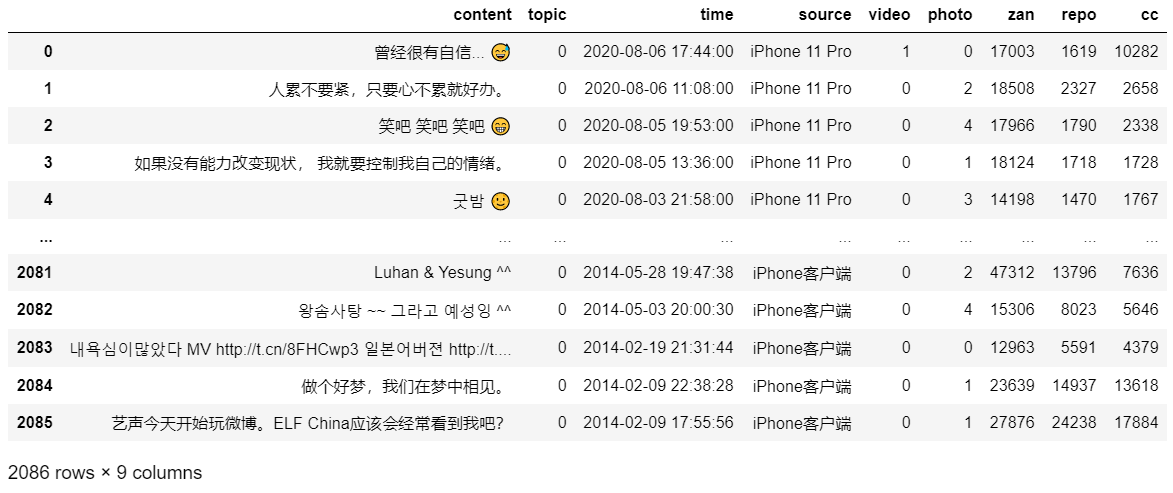
清洗过后获得的微博内容如下图,以@yesung110684(Super Junior - 艺声)的数据为示例:
后续待开展项目包括:
- 微博分析及可视化 :预计以@yesung110684(Super Junior - 艺声)的数据为示例,分析yesung发博的密集时间段,提及队友次数,转赞评变化等。
爬虫框架
- 提供网页url
- 获取网页源代码
- 网页存储
- 读取网页
- 网页解析并分析
- 清洗数据并存储
1 提供网页url:url选择非触屏手机网页版weibo,因为电脑版网页及手机触屏版网页使用javascript动态网页,需要使用selenium爬取。为了方便操作,优先选择只需requests就可爬取的非触屏手机网页版。
1
2
3
user = 'yesung'
user_url = 'https://weibo.cn/u/5029399338'
maxp = 212
2 获取网页源代码:使用requests module中的Session.get,提供自己的微博cookie,模拟真实浏览器操作。 3 网页存储:将所有网页以f’{user} {page}.html’的形式存储到’\user\user grab time’的文件夹里。其中user grab time的文件夹创立是为了分别针对同一用户在不同时间点做出的多次爬取,比如当需要分析该用户在一段时间内粉丝,或某微博的转赞评涨幅(“发大水”程度)时。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def store_user_pages(user_name, user_url, maxp, minp = 1):
'''
Reads the user's assigned pages of weibo
Input:
- user's name(str) used as file name,
- user's whichever-page url (str),
- the range of pages you want to grab: minp(int), maxp(str)
Output: all the weibo pages stored in folder created at the time the function is requested
'''
# get the url_list
clean_url = re.sub(r'\?.+?=.+?', '', user_url)
url_list = [clean_url + '?page=' + str(page) for page in range(minp, maxp+1)]
# set request session
headers = {
# pretend I am a browser
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
'cookie': '_T_WM=34953442506; SCF=Ajk-YV78pP2M6RQSDe4wfly_80RM9Q-4QymuM7cR3PdtCVC_zNKISHgzwvdCHM_kaiOGv3aTY_4BOv21hRAMiq0.; SUB=_2A25yj94CDeRhGeBP71QX-CbKzz6IHXVuc-JKrDV6PUJbktANLUL6kW1NRUxjc1DvrIOejhkvv8vmZCt1pSz-euBg; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhsbQaHX4CfzZMfTWwKPfgk5NHD95QceKBcSonRSoBEWs4Dqcj.i--Xi-z4iKL2i--ciKLhiKL2i--Xi-zRiKn7i--fiKn4iK.p; SUHB=0bt8gOFsGDjHnO; SSOLoginState=1602989650; WEIBOCN_FROM=1110103030; MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3D10000011%26lfid%3D1076035029399338%26fid%3D1005055029399338%26uicode%3D10000011; XSRF-TOKEN=98e6c5'
}
session = requests.Session()
# set folder and file_name(file_name = 'username page_num.html')
zfill_n = len(str(maxp - minp))
folder_name = user_name + ' ' + str(datetime.datetime.now().strftime('%Y-%m-%d %H_%M'))
folder_path = os.getcwd()+'\\'+ user_name + '\\' + folder_name
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# save all the weibo pages in this folder
for url in url_list:
page = session.get(url, headers = headers)
soup = BeautifulSoup(page.text)
file_name = user_name + ' ' + str(minp).zfill(zfill_n) + '.html'
name_wdir = os.path.join(folder_path, file_name)
with open(name_wdir, "w", encoding='utf-8') as f:
f.write(str(soup))
time.sleep(np.random.randint(1,2) + np.random.random())
minp += 1
4 读取网页:既然网页存在不同的文件夹里,则读取网页时必须首先使用get_folders()确定有哪些可选的文件夹,选定一个文件夹folder_idx,再读取其中的全部。
1
2
3
4
5
6
7
8
9
10
11
def get_folders(user):
# Get list folders that contain weibos
all_items = os.listdir(os.getcwd()+ f'\\{user}')
folder_bool = [True if (re.match(f'^{user}', file) is not None) & (re.match(r'.+?\.html$', file) is None) else False for file in all_items]
folder_list = []
for idx in range(len(all_items)):
if folder_bool[idx] == True:
folder_list.append(all_items[idx])
return folder_list
folder_idx = 0 # you choose
5 网页解析并分析:使用beautifulsoup解析为soup,提取有用部分包括:
-
用户信息
get_basic_info(user, folder_idx):用户名,基本信息,简介,粉丝数,关注,微博数量,微博总页数;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
<br> ```python def get_basic_info(user, folder_idx): file = glob.glob(f'{user}'+ '\\'+ get_folders(user)[folder_idx] + '\\*.html')[0] page = open(file, "r", encoding="utf-8").read() soup = BeautifulSoup(page) info = soup.find('span', {'class': 'ctt'}) user_alias = info.img.parent.get_text().strip(info.span.string).split('\xa0')[0] basic = ''.join((info.img.parent.get_text().strip(info.span.string).split('\xa0')[1]).split()) renzheng = soup.find('div', class_ = 'u').find_all('span', class_ = 'ctt')[1].text descrp = soup.find('div', class_ = 'u').find_all('span', class_ = 'ctt')[2].text tip2 = soup.find('div', class_ = 'tip2') weibo_num, follow, follower = re.findall('[0-9]+', tip2.text)[:3] maxpage = int(soup.find('input', {'name': 'mp'})['value']) basic_dict = dict({'user_alias':user_alias, 'basic': basic, 'certify': renzheng, 'desciption': descrp, 'weibo_cnt':weibo_num, 'follow':follow, 'follower':follower, 'maxpage': maxpage}) return basic_dict ``` -
微博内容
read_user(user, folder_idx): 内容content,时间time,形式(有无视频video,有多少张图片photo),赞zan,转repo,评cc。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
```python def read_user(user, folder_idx): # Reads the user's assigned pages of weibo # Input: user's url - htm, the number of first pages you want to grab # Output: dataframe for all the weibos weibo_df = pd.DataFrame() file_list = glob.glob(f'{user}'+ '\\'+ get_folders(user)[folder_idx] + '\\*.html') for file_name in file_list: page = open(file_name, "r", encoding="utf-8").read() soup = BeautifulSoup(page) cards = get_cards(soup) weibo_df = weibo_df.append(read_card(cards)).reset_index(drop = True) return weibo_df def get_cards(soup): cards = soup.find_all('div', {'class': 'c', 'id': not None}) return cards def read_card(cards): # This function can read the weibo contents, release time, source, media, and responses on 1 page # Input: cards(all the divs on 1 weibo page) # Output: a dataframe card_dict = dict(card_info(basic_info['user_alias'], cards), **card_media(cards), **card_zzp(cards)) return pd.DataFrame(card_dict) def card_info(user_alias, cards): video_text = user_alias + '的微博视频' content = [card.div.span.text.split(video_text)[0] if card.div.span.text is not None else None for card in cards] tm = [card.find('span', class_='ct').text.split('\xa0来自')[0] for card in cards] source = [card.find('span', class_='ct').text.split('\xa0来自')[1] for card in cards] return dict({ 'content': content, 'time': tm, 'source': source }) def card_media(cards): video_col = [card.div.span.find_all('a')[-1].text if (card.div.span.a is not None) else '0' for card in cards] video = [1 if (re.search('视频', unit) is not None) else 0 for unit in video_col] photo_col = [card.find_all('a')[0] if (re.findall('图',card.find_all('a')[0].text) != [])|(card.find_all('a')[0].find('img') is not None) else 0 for card in cards] photo = [] for this_photo in photo_col: if type(this_photo) == int: photo.append('0') else: if re.findall('图',this_photo.text) != []: photo.append(re.findall('[0-9]+', this_photo.text)[0]) else: photo.append('1') photo = [*map(lambda x: int(x), photo)] return dict({ 'video': video, 'photo': photo }) attitude_reg = re.compile(r'^https://weibo.cn/attitude/') repost_reg = re.compile(r'^https://weibo.cn/repost/') cc_reg = re.compile(r'^https://weibo.cn/comment/') def card_zzp(cards): zans = [card.find_all('a', href = attitude_reg)[0] for card in cards] zan_nums = [int(re.findall('[0-9]+',zan.text)[0]) for zan in zans] repos = [card.find_all('a', href = repost_reg)[0] for card in cards] repo_nums = [int(re.findall('[0-9]+',repo.text)[0]) for repo in repos] ccs = [card.find_all('a', href = cc_reg)[0] for card in cards] cc_nums = [int(re.findall('[0-9]+', cc.text)[0]) for cc in ccs] return dict({ 'zan': zan_nums, 'repo': repo_nums, 'cc': cc_nums }) ```
6 清洗数据并存储:
-
时间类型转换 :微博显示的时间中,非当年的年份以标准方式表示,同年微博以中文月日时表示,如’01月1日 15:14’表示2020年1月1日 15:14发出,而2019年的则表示为’2019-12-31 22:11:15’;
-
float类型转换 :从video到cc的倒数五列都被保存为了float,用astype改为int;
-
提取tag数量 :从content中用正则表达式r’#[0-9\w]’匹配tag,用finditer提取匹配次数;
1 2 3 4 5 6 7 8 9 10 11 12 13
def get_data_dictionary(): # 获得数据词典 content_d = 'content: 微博内容\n' topic_d = 'topic: 该微博中含有的话题数量\n' time_d = 'time: 该微博发出的时间点\n' source_d = 'source: 该微博发出的来源,如iPhone客户端\n' video_d = 'video: 该微博是否含有视频,1为是,0为否\n' photo_d = 'photo: 该微博含有的图片数量\n' reaction_d = 'zan, repo, cc: 该微博在爬虫时间点获得的赞、转、评数量' data_dict = 'Data Dictionary:\n\n' + content_d + topic_d + time_d + source_d + video_d + photo_d + reaction_d return data_dict
1 2 3 4 5
def change_time_format(release_time): if release_time.find('日') != -1: release_time = str(datetime.datetime.now().year) + '年' + release_time release_time = datetime.datetime.strptime(release_time, '%Y年%m月%d日 %H:%M') return release_time
1 2 3 4 5 6 7 8 9
def clean_dateframe(user_weibo, file_location, file_prefix): # 清洗数据框并将数据框xlsx与数据词典txt保存在指定位置 user_weibo.time = user_weibo.time.apply(change_time_format) # 时间转换 user_weibo[user_weibo.columns[-5:]] = user_weibo[user_weibo.columns[-5:]].astype(int) # int转换 topic = user_weibo.content.apply(lambda x: len([*re.finditer(r'\#[0-9\w]', x)])) user_weibo.insert(1, 'topic', value = topic) # 增加tag数量 user_weibo.to_excel(file_location + f'\\{file_prefix} weibo status.xlsx') # 保存微博内容数据框 with open(file_location + '\\data dictionary.txt') as f: f.write(get_data_dictionary()) # 保存数据词典
清洗后的微博内容数据框如下图: